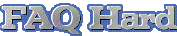Технология Hyper-Threading существовала и ранее вне x86 мира в виде технологии одновременной многопоточности (Simultaneous Multi-Threading, SMT).
Идея этой технологии проста.
Один физический процессор представляется операционной системе как два логических процессора, и операционная система не видит разницы между одним SMT процессором или двумя обычными процессорами.
В обоих случаях операционная система направляет потоки как на двухпроцессорную систему.
Далее все вопросы решаются на аппаратном уровне.
Работа множества потоков достигается за счет дублирования архитектурных состояний (логических процессоров) при совместном использовании единого набора ресурсов процессора.
В процессоре с Hyper-Threading каждый логический процессор имеет свой собственный набор регистров (включая и отдельный счетчик команд), а чтобы не усложнять технологию, в ней не реализуется одновременное выполнение инструкций выборки/декодирования в двух потоках.
То есть такие инструкции выполняются поочередно.
Параллельно же выполняются лишь обычные команды.
Проблема неполного использования исполнительных устройств связана с несколькими причинами.
В результате недостаточной пропускной способности системной шины и шины памяти процессор не может получать данные с желаемой скоростью и исполнительные устройства будут использоваться не так эффективно.
Кроме того, существует ещё одна причина — недостаток параллелизма на уровне инструкций в большинстве потоков выполняемых команд.
Большинство производителей улучшают скорость работы процессоров путем увеличения тактовой частоты и размеров кэша.
Конечно, таким способом можно увеличить производительность, но все же потенциал процессора не будет полностью задействован.
Если бы мы могли одновременно выполнять несколько потоков, то мы смогли бы использовать процессор куда более эффективно.
Именно в этом и заключается суть технологии Hyper-Threading.
Программные приложения, способные работать с несколькими процессорами, могут без модификаций выполняться на удвоенном числе логических процессоров, имеющихся в системе.
Каждый логический процессор может отвечать на прерывания независимо от других.
Первый логический процессор может отслеживать потоки одной программы, в то время как второй будет заниматься потоками другой программы.
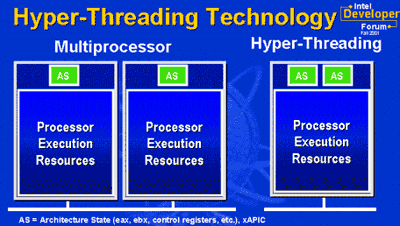
Поскольку оба процессора совместно используют единый набор ресурсов исполнения, второй поток может задействовать ресурсы, которые при обработке всего одного потока простаивали бы.
Здесь же мы получаем увеличение загрузки ресурсов исполнения в пределах каждого физического процессора.
Такое улучшение использования ресурсов процессора приводит к повышению пропускной способности при обработке многопоточных приложений.
Например, один логический процессор может выполнять операции с плавающей точкой, а второй в это же время выполняет сложение и операцию загрузки, т.е. могут исполняться два задания или два фрагмента кода одной программы.
Забиваем Сайты В ТОП КУВАЛДОЙ - Уникальные возможности от SeoHammer
Каждая ссылка анализируется по трем пакетам оценки:
SEO, Трафик и SMM.
SeoHammer делает продвижение сайта прозрачным и простым занятием.
Ссылки, вечные ссылки, статьи, упоминания, пресс-релизы - используйте по максимуму потенциал SeoHammer для продвижения вашего сайта.
Что умеет делать SeoHammer
— Продвижение в один клик, интеллектуальный подбор запросов, покупка самых лучших ссылок с высокой степенью качества у лучших бирж ссылок.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию
Буст, она ускоряет продвижение в десятки раз,
а первые результаты появляются уже в течение первых 7 дней.
Зарегистрироваться и Начать продвижение
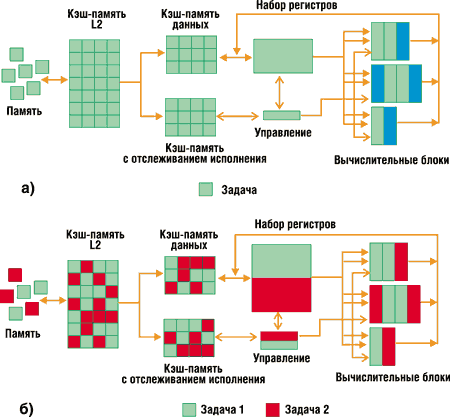
Большинство ресурсов исполнения сосредоточено в блоке быстрого исполнения (Rapid Execution Engine) и встроенной кэш-памяти, которые одновременно обрабатывают инструкции от двух потоков.
Механизм выборки и доставки (Fetch and Deliver engine) и блок переупорядочения и изъятия (Reorder and Retire) выделяют ресурсы, которые поочередно предоставляются в распоряжение обоих потоков.
Механизм выборки и доставки
Этот механизм организует поочередную выборку инструкций то из одного логического процессора, то из другого и пересылает эти инструкции в блок быстрого исполнения (Rapid Execution Engine) для обработки.
На первом уровне кэш-памяти (Execution Trace Cache) поочередно делается выборка по одной строке на каждый логический процессор.
Это происходит в том случае, если оба логических процессора нуждаются в этой кэш-памяти.
Если один из логических процессоров не запрашивает использование кэш-памяти, то другой может воспользоваться полной полосой пропускания этого типа кэш-памяти.
Rapid Execution Engine
Оба логических процессора используют модуль быстрого исполнения одновременно.
Этот блок принимает инструкции из очередей и с максимальной скоростью пересылает их в операционные модули.
Выбор инструкций зависит только от степени их соподчиненности и готовности функциональных модулей.
Выборка инструкций может выполняться в произвольном порядке, т.е. более поздние, но независимые инструкции могут пройти впереди более ранних.
Ядру исполнения по большей части «очевидно», какие из инструкций какому логическому процессору принадлежат, а планировщики не различают инструкций от различных логических процессоров — они просто переназначают независимые очереди инструкций на доступные для выполнения ресурсы.
Например, планировщик может за один цикл диспетчеризовать две инструкции из потока №1 и одну инструкцию из потока №2.
Встроенная кэш-память
Поскольку подсистема встроенной кэш-памяти тактируется частотой ядра процессора, то по мере выпуска более быстрых процессоров соответственно будет возрастать и скорость этого типа памяти, обеспечивающего высокоскоростной доступ к важнейшим данным.
Большие размеры линий кэширования также снижают среднее число промахов.
Встроенные подсистемы кэширования, совместно используемые всеми логическими процессорами, помогают минимизировать потенциальные конфликты благодаря использованию высокого уровня ассоциативности наборов инструкций.
Совместное использование кэш-памяти также ускоряет работу некоторых приложений в ситуациях, когда один логический процессор способен осуществлять выборку инструкций или данных в кэш-память для другого логического процессора.
При этом другому логическому процессору не приходится повторно обращаться к системной шине и запрашивать инструкции или данные из системной памяти.
Сервис онлайн-записи на собственном Telegram-боте
Попробуйте сервис онлайн-записи VisitTime на основе вашего собственного Telegram-бота:
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно.
Зарегистрироваться в сервисе
Блок переупорядочения и изъятия
Этот блок принимает все инструкции, которые выполнялись в произвольном порядке, и сортирует их в соответствии с порядком, определенным программой, а затем фиксирует их в этом состоянии.
Изъятие инструкций происходит попеременно между логическими процессорами.
Системная шина
Высокоскоростная системная шина с тактовой частотой 400 МГц предназначена для увеличения пропускной способности многопроцессорных и многопотоковых серверных приложений.
Она обеспечивает необходимую полосу пропускания для технологии Hyper-Threading при доступе к системной памяти.
Эта шина использует схемы сигнализации и буферизации, обеспечивающие высокоскоростную передачу данных и позволяющие расширить полосу пропускания до 3,2 Гбайт/с.
Когда один из логических процессоров не может найти требуемые данные во встроенной кэш-памяти, то эти данные должны быть переданы из памяти именно по системной шине.
Поддержка Hyper-Threading в Pentium 4
Для повышения производительности и пропускной способности современных приложений в семействе процессоров Intel Xeon технология Hyper-Threading используется совместно с микроархитектурой NetBurst.
В первые технология Hyper-Threading реализована в модели c рабочей частотой 3.06 ГГц.
Этот процессор создан по технологии 0.13 мкм, имеет ядро Northwood, кэш-память второго уровня (L2) 512 Кбайт, рабочую частоту 3.06 ГГц, рассчитан на работу в системах с процессорной шиной 533 МГц (тактовая частота FSB 133 МГц, что обеспечивает частоту передачи данных 533 МГц) и ориентирован на рынок настольных компьютеров.
Производительность систем с Hyper-Threading может повышается на 30 %.
Поддержка Hyper-Threading ОС
Поддержка технологии Hyper-Threading осуществляется многозадачными операционными системами. Например, Linux (с версии ядра 2.4) и Windows XP.
А вот Windows 95/98/ME для этих целей уже не подходят.
Windows NT, обладающая поддержкой SMP (Symmetric Multi-Processor), увидеть второй логический процессор в новом Pentium 4 также не сможет: это связано с отсутствием в этой ОС поддержки ACPI.
В силу своих корней, этой поддержкой обладают все ОС, основанные на идеологии Unix — всевозможные Free- Net- BSD, коммерческие Unix (такие как Solaris, HP-UX, AIX), и многочисленные разновидности Linux.
Корпорация Microsoft разродилась официальным документом, из которого мы можем уяснить множество полезной информации, как, в частности:
• В настоящее время технологию Hyper-Threading могут нормально использовать (не путать с полной поддержкой!) все версии Windows 2000, а также все 32-битные версии Windows XP и Windows .NET Server.
В других операционных системах данная технология не поддерживается.
• Для получения максимальной производительности необходимо выставлять в листинге BIOS в порядке загрузки первые логические процессоры физических CPU, и только затем — вторые логические процессоры.
Пример: у вас — двухпроцессорная система с поддержкой Hyper-Threading.
Соответственно, у вас — четыре логических процессора (к примеру, logCPU1a, logCPU1b, logCPU2a, logCPU2b).
В создаваемой BIOS таблице — Multiple APIC Description Table описывается конфигурация, и вот здесь-то вам необходимо вначале указать ПЕРВЫЕ логические процессоры физических CPU, то есть в таком порядке: logCPU1a, logCPU2a, logCPU1b, logCPU2b.
Это — перестраховка, и при прочих равных условиях гарантирует вам лучшую производительность.
• Что касается Windows 2000 (все версии), то в данной операционной системе механизм распознавания процессоров не поддерживает точную идентификацию CPU с поддержкой Hyper-Threading.
Это касается в том числе и систем с установленными текущими наборами Service Pack.
Более того, в данной системе и в дальнейшем НЕ планируется вводить идентификацию CPU с поддержкой Hyper-Threading (т.е. в новых Service Pack'ах).
Однако работоспособность системы Windows 2000 с Hyper-Threading реализована в полной мере.
Например, если у вас — Windows 2000 Professional и один физический процессор с поддержкой Hyper-Threading, то система будет работать с двумя реализованными в нём логическими процессорами (так как лицензия Windows 2000 Professional распространяется на два процессора).
При установке двух CPU Hyper-Threading под 2000 Professional вам придётся указывать только первые логические процессоры, как и было описано выше.
Соответственно, Windows 2000 распознаёт логические процессоры в CPU с поддержкой Hyper-Threading как отдельные физические, и вам необходимо следить за их количеством:
— Windows 2000 Professional: 2
— Windows 2000 Standard Server: 4
— Windows 2000 Advanced Server: 8
— Windows 2000 Datacenter Server: 32
• Что касается Windows XP и Windows .NET Server (все 32-битные версии), то здесь — ситуация более благоприятная.
Операционная система использует обновлённые технологии распознавания процессоров Intel и вы получаете прямые выгоды от работы с Hyper-Threading.
Проблем с лицензией не будет — она привязана только к числу физических процессоров, при полной поддержке всех логических CPU.